Last year I benchmarked a few ways of shuffling columns in a data.table, but what about pandas? I didn’t know, so let’s revisit those tests and add a few more operations! pandas winds up being much more competitive than I expected.
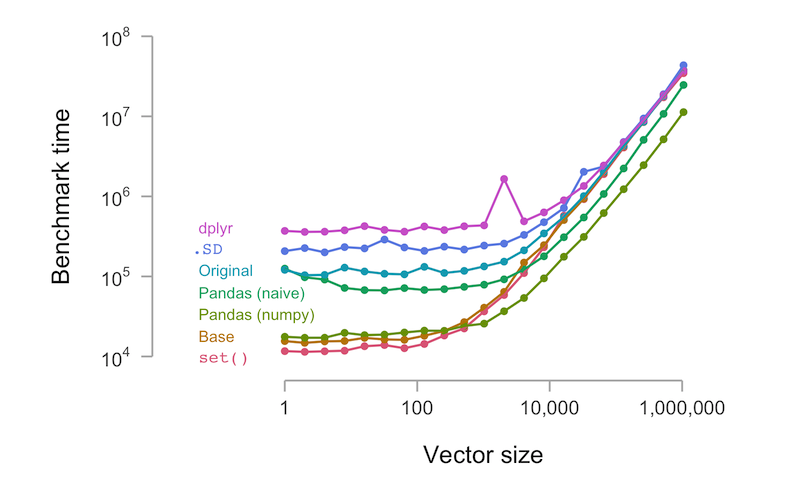
First, dplyr is by far the slowest. Second, pandas is (more than) competitive with the R options. In the small-size regime (vector sizes up to about 1,000), the pandas option is similar to, but faster than, most of the slower R options, and the numpy-backed solution is nearly as fast as base R assignment and data.table’s in-place option. I expected pandas to be a lot slower.
More surprising, in the large-vector regime both Python solutions outperform all R options, and the in-place Python option is much faster than everything else, starting with vector sizes of about 10,000. I’m not sure how representative this benchmark is, but it’s an interesting data point.
More than most frameworks, pandas feels sensitive to the
way we do something: calling .apply() isn’t just a little
slower than .transform()—it’s miles slower. So the simple
transformations we’re doing here are pretty easy to optimize;
and numpy-backed operations should be fast anyway.
There also might be systematic differences between R and Python tests: R functions are tested using microbenchmark and Python tests were run with timeit. New code is below.
New Python testing code
from timeit import Timer
import pandas as pd
def scramble_naive(df: pd.DataFrame, colname: str) -> pd.DataFrame:
df[colname] = df[colname].sample(frac=1, ignore_index=True)
return df
test_naive = "scramble_naive(df, colname='x')"
results_naive = {
n: Timer(test_naive, setup % n).repeat(repeat=100, number=1)
for n in range(21)
}
import numpy as np
import pandas as pd
def scramble_inplace(df: pd.DataFrame, colname: str) -> pd.DataFrame:
np.random.shuffle(df[colname].to_numpy())
return df
test_inplace = "scramble_naive(df, colname='x')"
results_inplace = {
n: Timer(test_inplace, setup % n).repeat(repeat=100, number=1)
for n in range(21)
}
New R testing code
scramble_base <- function(input_df, colname) {
input_df[[colname]] <- sample(input_df[[colname]])
input_df
}
library(dplyr)
scramble_dplyr <- function(input_tbl, colname) {
input_tbl %>% mutate({{colname}} := sample(.data[[colname]]))
}
This post and others like it are kindly republished by R-bloggers.
This post and others like it are kindly republished by Python-bloggers.